Implementação de DataProviders
Objetivos
- Compreender conceitualmente o que são *DataProviders* e *Sources*.
- Aprender a utilizar um *DataProvider* customizado implementando a interface *IDataProvider*.
- Compreender o que se perde ao utilizar um *DataProvider* customizado.
- Compreender as diferenças de um *DataProvider* para sources do tipo “table” e do tipo “*contentTable*”.
- Aprender a utilizar as informações de contexto que são fornecidas em uma classe que implementa uma interface *IDataProvider*.
Referências complementares
- Ciclo de vida de uma interface
- DOUI
- DOUI versus Content
- Source
Conceito
O que é um DataProvider?
*DataProvider* é o responsável por prover dados que são carregados de qualquer fonte de dados e populados em um ou mais *Sources*. Os dados podem ser carregados de diversas fontes, como tabelas de banco de dados, lista de objetos, arquivo texto, arquivo *XML* ou *Web Services*, entre outros.
O que é um Source?
Um *Source* é a representação de uma fonte de dados que é utilizada pelos controles para obter seus dados de renderização. Os Sources têm seus dados populados a partir de um *DataProvider*. Embora nada impeça que controles obtenham seus dados de outras fontes como API’s, cookies ou valores da sessão, tipicamente os dados apresentados nas interfaces são obtidos através de *Sources* e *DataProviders*.
A classe *Source* possui um ou mais campos, que servem para identificar os elementos de dados do *Source*. A classe *TabularSource* estende a classe Source, dando uma semântica tabular aos dados, ou seja, organizando-os em linhas e colunas (campos).
Há ainda a classe *TableSource*, que estende *TabularSource*, caracterizando uma fonte de dados tabulares provenientes de uma tabela de banco de dados, mapeando as linhas e campos do Source para registros e colunas da tabela. Ela trabalha em conjunto com a interface *ITableDataProvider*, que estende *IDataProvider*, representando um *DataProvider* que obtém os dados para um *Source* através de consultas a uma tabela de banco de dados.
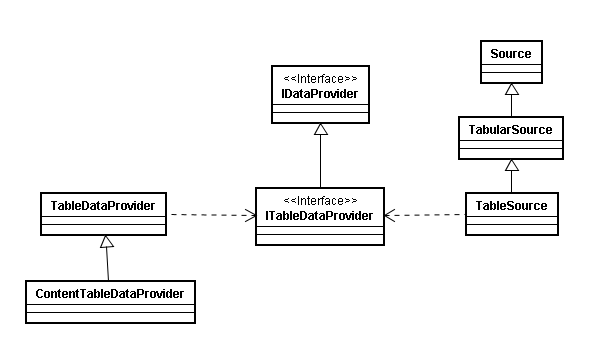
Para utilizar um *TableSource*, no arquivo “douidefinition.xml” do serviço, deve ser especificado no atributo *“type”* do elemento *“source”* um dos valores: table, contentTable ou view.
Quando o valor definido for “table”, este Source será carregado diretamente de uma tabela de banco de dados e quando precisar gravar dados, somente a tabela definida no nó *“table”* será populada.
Quando o valor for *“contentTable”* este *Source* será carregado a partir de uma tabela de banco de dados junto com outras informações de metadados do Lumis e quando precisar gravar dados será populado a tabela definida no nó “*table*” e as tabelas complementares de metadados do Lumis.
É importante destacar que o elemento responsável pela persistência dos dados é o process action configurado na interface, seja para inserção, atualização ou remoção. A utilização de tipos de sources incoerentes com os tipos dos process actions definidos levará a geração de inconsistências nos dados.
É fundamental que, para sources do tipo “table”, sejam utilizados os process actions de mesmo tipo (tableAddData, tableUpdateData e tableDeleteData), que acessam apenas a tabela definida no nó “table”.
Para sources do tipo “contentTable”, por sua vez, devem ser utilizados os process actions do tipo content (contentTableAddData, contentTableUpdateData e contentTableDeleteData), que também tratam a persistência dos metadados.
Quando o valor definido for “view”, este Source será carregado a partir de uma consulta de banco de dados (VIEW) e neste caso, este source serve somente para leitura, não é possível gravar dados em uma VIEW.
A implementação de *IDataProvider* default é um
Como Utilizar um DataProvider Customizado em um Source
Para utilizar um DataProvider customizado, deve-se, na definição do *Source*, especificar no elemento “*dataProviderClassName*” o nome da classe que implementa a interface *IDataProvider*. Dessa forma, ao invés do *TableSource* utilizar sua forma padrão de leitura de dados (TableDataProvider), o IDataProvider especificado será chamado para obter os dados e carregá-los no *Source*.
Primeiramente, vamos ver como é declarado um *Source* default:
<source id="apuracao" type=”table”>
<table>Apuracao</table>
<fields>
<field id="name" dataType="string" name="Nome" />
<field id="uf" dataType="string" name="Estado" />
<field id="percentVotes" dataType="string" name="Percentual de Votos" />
</fields>
</source>Neste caso a classe TableSource, que estende da classe Source, deve carregar seus dados através da classe TableDataProvider que utiliza o elemento “table” na definição do source para indicar qual a tabela do banco de dados de onde serão lidas as informações.
<source id="apuracao" type=”contentTable”>
<table>Apuracao</table>
<fields>
<field id="name" dataType="string" name="Nome" />
<field id="uf" dataType="string" name="Estado" />
<field id="percentVotes" dataType="string" name="Percentual de Votos" />
</fields>
</source>Na definição acima, a classe chamada para carregar os dados não é a *TableSource*, mas a *ContentTableSource*, que estende a classe *TableSource*. A *ContentTableSource*, por sua vez, carrega seus dados através da classe *ContentTableDataProvider*, que utiliza o elemento “table” na definição do source para indicar que tabela do banco de dados será lida. Neste caso a API do Lumis carrega também as informações de metadados deste Source, relacionando no banco de dados com várias tabelas que guardam as informações sobre metadados.
Agora, vejamos como declarar um *DataProvider* customizado para ser utilizado em um Source:
<source id="apuracao">
<dataProviderClassName>br.com.lumis.artigos.dataprovider.ApuracaoVotacaoDataProvider</dataProviderClassName>
<fields>
<field id="name" dataType="string" name="Nome" />
<field id="uf" dataType="string" name="Estado" />
<field id="percentVotes" dataType="string" name="Percentual de Votos" />
</fields>
</source>Veja que no exemplo acima não é declarado o atributo “type”, o Source será carregado de uma classe de DataProvider que implementa a interface IDataProvider.
Abaixo segue exemplo de uma Interface cujo Source foi carregado de um DataProvider. A imagem mostra os dados carregados de um arquivo de XML, mas a fonte de dados poderia ser carregada de outros lugares como, por exemplo, um banco de dados.
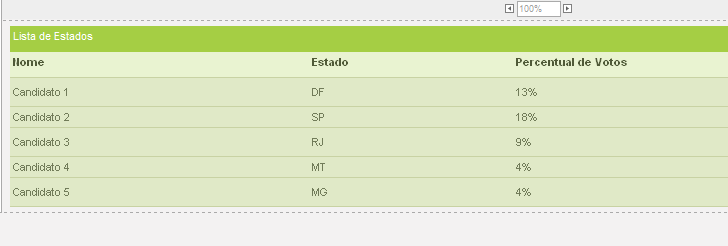
Veja a estrutura do XML que popula o Source da interface acima:
<?xml version="1.0" encoding="UTF-8" ?>
<result>
<totalVotes>1100</totalVotes>
<candidate>
<name>Candidato 1</name>
<uf>DF</uf>
<votes>150</votes>
</candidate>
<candidate>
<name>Candidato 2</name>
<uf>SP</uf>
<votes>200</votes>
</candidate>
<candidate>
<name>Candidato 3</name>
<uf>RJ</uf>
<votes>100</votes>
</candidate>
<candidate>
<name>Candidato 4</name>
<uf>MT</uf>
<votes>50</votes>
</candidate>
<candidate>
<name>Candidato 5</name>
<uf>MG</uf>
<votes>50</votes>
</candidate>
</result>Veja abaixo a implementação da classe do DataProvider que carrega os dados acima:
package br.com.lumis.artigos.dataprovider;
import java.io.File;
import lumis.doui.source.IDataProvider;
import lumis.doui.source.ISourceData;
import lumis.doui.source.TabularData;
import lumis.doui.source.TabularSource;
import lumis.portal.PortalException;
import lumis.portal.authentication.SessionConfig;
import lumis.util.ITransaction;
import lumis.util.XmlUtil;
import org.w3c.dom.Document;
import org.w3c.dom.Node;
public class ApuracaoVotacaoDataProvider implements IDataProvider<TabularSource<?>>{
@Override
public void loadData(SessionConfig sessionConfig, TabularSource<?> source,
ITransaction transaction) throws PortalException {
File result = new File("c:\\result.xml");
Document resultDom = XmlUtil.getDocument(result);
Node[] candidateNodes = XmlUtil.selectNodes("result/candidate", resultDom);
Integer totalNode = XmlUtil.readNodeInteger("result/totalVotes", resultDom, 0);
TabularData tabularData = source.getData();
for(Node candidateNode : candidateNodes){
ISourceData row = tabularData.addRow();
String nome = XmlUtil.readNodeString("name", candidateNode);
String uf = XmlUtil.readNodeString("uf", candidateNode);
Integer votes = XmlUtil.readNodeInteger("votes", candidateNode, 0);
String percent = (int)((votes.floatValue() / totalNode) * 100) + "%";
row.put("name", nome);
row.put("uf", uf);
row.put("percentVotes",percent );
}
}
}No exemplo, a classe *ApuracaoVotacaoDataProvider* implementa o método “loadData()” que é o responsável por carregar os dados para o *Source*.
public void loadData(SessionConfig sessionConfig, TabularSource<?> source, ITransaction transaction) throws PortalException {O método “*getData()*” retorna um objeto *TabularData*, que possui uma Lista *ISourceData*, inicialmente vazia e que deve ser populada com objetos SourceData através da iteração que se segue no código.
TabularData tabularData = source.getData();O método “addRow()” cria uma nova instância de SourceData a cada iteração , adiciona a instância nova de SourceData à lista de ISourceData contidos na classe TabularData e retorna este objeto SourceData para que seja populado com os campos lidos do XML.
ISourceData row = tabularData.addRow();
String nome = XmlUtil.readNodeString("name", candidateNode);
String uf = XmlUtil.readNodeString("uf", candidateNode);
Integer votes = XmlUtil.readNodeInteger("votes", candidateNode, 0);
String percent = (int)((votes.floatValue() / totalNode) * 100) + "%";
row.put("name", nome);
row.put("uf", uf);
row.put("percentVotes",percent );
O que se perde ao utilizar um DataProvider customizado
Quando se implementa um DataProvider customizado, as funcionalidades, Número de Itens (Paginação), Ordenação e Filtros deixam de funcionar de forma nativa (default). Se quisermos utilizar estas funcionalidades é necessário implementá-las na classe de DataProvider customizado. A seguir mostraremos alguns exemplos de implementações.
Paginação
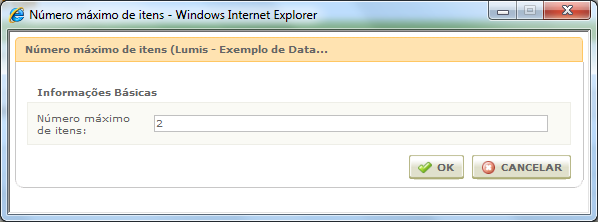
Primeiro, precisamos definir o número de itens que será apresentado por página:

Definimos em 2 a quantidade de itens que será carregado a cada página de registros:
 Implementação
Implementação
@Override
public void loadData(SessionConfig sessionConfig, TabularSource<?> source,
ITransaction transaction) throws PortalException {
File result = new File("c:\\result.xml");
Document resultDom = XmlUtil.getDocument(result);
Node[] candidateNodes = XmlUtil.selectNodes("result/candidate", resultDom);
Integer totalNode = XmlUtil.readNodeInteger("result/totalVotes", resultDom, 0);
TabularData tabularData = source.getData();
int totalRows = candidateNodes.length;
source.getData().setTotalRows(totalRows);
int startAt = source.getStartAt()-1;
int maxRows = source.getMaxRows();
for(int i = 0 ; i < maxRows; i++){
if(i+startAt <= totalRows-1){
Node candidateNode = candidateNodes[i+startAt];
ISourceData row = tabularData.addRow();
String nome = XmlUtil.readNodeString("name", candidateNode);
String uf = XmlUtil.readNodeString("uf", candidateNode);
Integer votes = XmlUtil.readNodeInteger("votes", candidateNode, 0);
String percent = (int)((votes.floatValue() / totalNode) * 100) + "%";
row.put("name", nome);
row.put("uf", uf);
row.put("percentVotes",percent );
}
}
}Para popular o Source é necessário especificar o número total de objetos:
int totalRows = candidateNodes.length;
source.getData().setTotalRows(totalRows);Pegar o registro inicial que será carregado:
int startAt = source.getStartAt()-1;Pegar o total de registros por página:
int maxRows = source.getMaxRows();
Buscar na fonte de dados o intervalo de registros especificado:
for(int i = 0 ; i < maxRows; i++){
if(i+startAt <= totalRows-1){
Node candidateNode = candidateNodes[i+startAt];
ISourceData row = tabularData.addRow();
String nome = XmlUtil.readNodeString("name", candidateNode);
String uf = XmlUtil.readNodeString("uf", candidateNode);
Integer votes = XmlUtil.readNodeInteger("votes", candidateNode, 0);
String percent = (int)((votes.floatValue() / totalNode) * 100) + "%";
row.put("name", nome);
row.put("uf", uf);
row.put("percentVotes",percent );
}
}Veja a seguir como fica a paginação:
Página 1

Página 2

Página 3

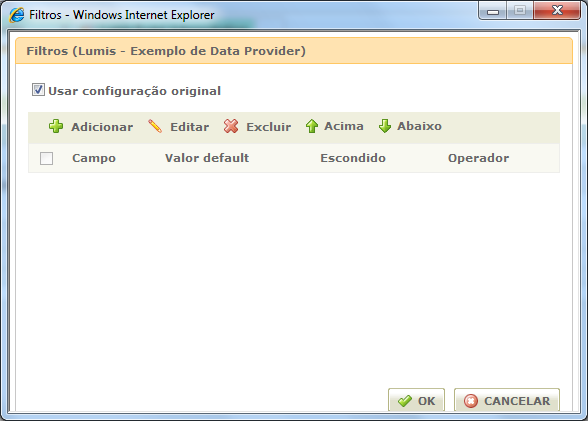
Primeiro precisamos definir os filtros na interface ou no arquivo douidefinition.xml do serviço:
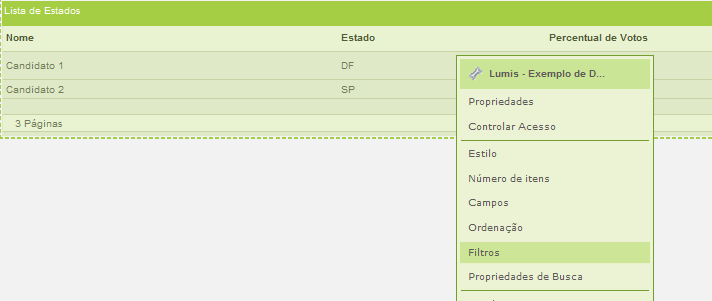
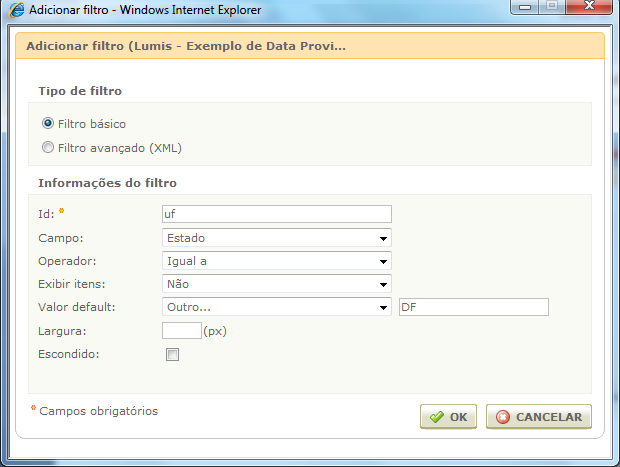
Adicionamos um filtro:
Implementação
@Override
public void loadData(SessionConfig sessionConfig, TabularSource<?> source,
ITransaction transaction) throws PortalException {
File result = new File("c:\\result.xml");
Document resultDom = XmlUtil.getDocument(result);
Node[] candidateNodes = XmlUtil.selectNodes("result/candidate", resultDom);
Integer totalNode = XmlUtil.readNodeInteger("result/totalVotes", resultDom, 0);
TabularData tabularData = source.getData();
int totalRows = candidateNodes.length;
for (Node node : candidateNodes) {
if(!(filterSource(node, getFilter(source))))
totalRows -= 1;
}
source.getData().setTotalRows(totalRows);
int startAt = source.getStartAt()-1;
int maxRows = source.getMaxRows();
for(int i = 0 ; i < maxRows; i++){
if(i+startAt <= totalRows-1){
Node candidateNode = candidateNodes[i+startAt];
if(filterSource(candidateNode, getFilter(source))){
ISourceData row = tabularData.addRow();
String nome = XmlUtil.readNodeString("name", candidateNode);
String uf = XmlUtil.readNodeString("uf", candidateNode);
Integer votes = XmlUtil.readNodeInteger("votes", candidateNode, 0);
String percent = (int)((votes.floatValue() / totalNode) * 100) + "%";
row.put("name", nome);
row.put("uf", uf);
row.put("percentVotes",percent );
}
}
}
}
public boolean filterSource(Node candidateNode, TableSourceFilter tableSourceFilter) throws PortalException {
if(tableSourceFilter.getSource().getParameterValue("uf").equals(XmlUtil.readNodeString("uf", candidateNode)))
return true;
return false;
}
public TableSourceFilter getFilter(TabularSource<?> source) throws PortalException {
TableSourceFilter tsf = new TableSourceFilter();
Node filtersNode = source.getFiltersNode();
if (filtersNode != null) {
Node[] filterNodes = XmlUtil.selectNodes("filter", filtersNode);
for (Node filterNode : filterNodes) {
String idFilter = XmlUtil.readAttributeString("id", filterNode);
if(idFilter.equals("uf"))
tsf = (TableSourceFilter) source.getFilter().getFilter(idFilter);
}
}
return tsf;
}Neste exemplo de implementação de filtro criamos o método “getFilter()”, que retorna um objeto TableSourceFilter com informações importantes como o “id” do filtro, o “fieldId” que é o campo que será filtrado e o “operator”, que indica qual operação (igual, diferente de, maior que, menor que, entre outros) está sendo utilizada no filtro.
Este método poderia retornar uma coleção de filtros. Repare que no trecho “Node[] filterNodes = XmlUtil.selectNodes("filter", filtersNode);” são retornados todos os filtros que estão dentro do nó “filters”. Neste exemplo, vamos pegar apenas o filtro com id=”uf” que declaramos na interface anteriormente. Veja o método a seguir:
public TableSourceFilter getFilter(TabularSource<?> source) throws PortalException {
TableSourceFilter tsf = new TableSourceFilter();
Node filtersNode = source.getFiltersNode();
if (filtersNode != null) {
Node[] filterNodes = XmlUtil.selectNodes("filter", filtersNode);
for (Node filterNode : filterNodes) {
String idFilter = XmlUtil.readAttributeString("id", filterNode);
if(idFilter.equals("uf"))
tsf = (TableSourceFilter) source.getFilter().getFilter(idFilter);
}
}
return tsf;
}Criamos outro método apenas para fazer a verificação de quais registros tem exatamente o valor passado no filtro, lembrando que queremos filtrar apenas os candidatos que sejam do estado “DF”.
public boolean filterSource(Node candidateNode, TableSourceFilter tableSourceFilter) throws PortalException {
if(tableSourceFilter.getSource().getParameterValue("uf").equals(XmlUtil.readNodeString("uf", candidateNode)))
return true;
return false;
}
Para que a lista não seja paginada de forma errada, precisamos informar ao Source qual o número exato de registros após o filtro.
int totalRows = candidateNodes.length;
for (Node node : candidateNodes) {
if(!(filterSource(node, getFilter(source)))){
totalRows -= 1;
}
}
source.getData().setTotalRows(totalRows);
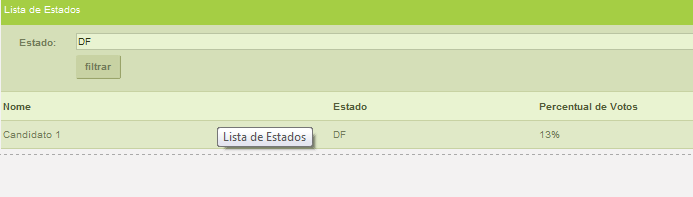
No final o Source deverá ser carregado apenas com os registros em que o campo “Estado” for igual a DF.
Ordenação
Para o exemplo de ordenação, vamos considerar que estamos buscando os dados de um banco de dados, onde a consulta às informações é feita usando-se SQL. Primeiramente, vamos definir a ordenação do Source:
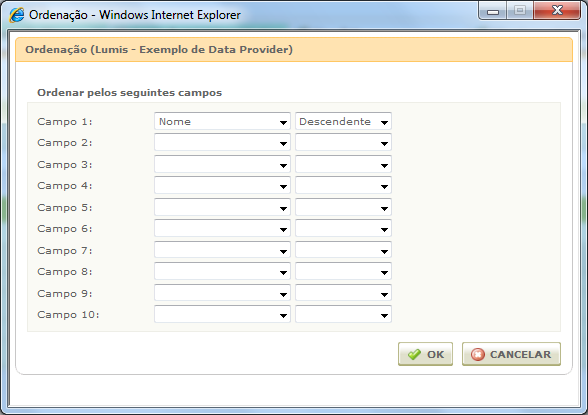
Neste exemplo, adquirimos os valores (id, direction) do XML que indicam por qual campo será ordenado e qual o sentido da ordenação.
Implementação
@Override
public void loadData(SessionConfig sessionConfig, TabularSource<?> source,
ITransaction transaction) throws PortalException {
Map<Object, String> orders = new HashMap<Object,String>();
Node orderNode = XmlUtil.selectSingleNode("orderBy", source.getDefinitionNode());
if (orderNode != null) {
Node[] fieldNodes = XmlUtil.selectNodes("field", orderNode);
for (Node fieldNode : fieldNodes) {
orders.put(XmlUtil.readAttributeString("id", fieldNode), "id");
orders.put(XmlUtil.readAttributeString("direction", fieldNode), "direction");
}
}
List<Candidate> candidates = new CandidateDao().getCandidates(transaction, orders);
TabularData tabularData = source.getData();
for(Candidate candidate : candidates){
ISourceData row = tabularData.addRow();
row.put("name", candidate.getName());
row.put("uf", candidate.getUf());
row.put("percentVotes", candidate.getVotes());
}
}Criamos neste exemplo uma classe CandidateDao e implementamos o método que faz a consulta ao banco de dados utilizando as informações da ordenação. Veja o código abaixo:
public List<Candidate> getCandidates(ITransaction transaction, Map<Object, String> orders) {
try {
ITransactionJdbc daoTransactionJdbc = (ITransactionJdbc) transaction;
Connection connection = daoTransactionJdbc.getConnection();
List<Candidate> candidates = new ArrayList<Candidate>();
StringBuilder query = new StringBuilder();
query.append("select name, uf, votes from APURACAO");
if(!orders.isEmpty()){
query.append("order by " + (String)orders.get("id")).append(" ").append((String)orders.get("direction"));
}
PreparedStatement statement;
try {
statement = connection.prepareStatement(query.toString());
ResultSet resultSet = statement.executeQuery();
while(resultSet.next()){
Candidate candidate = new Candidate();
candidate.setName(resultSet.getString("name"));
candidate.setUf(resultSet.getString("uf"));
candidate.setVotes(resultSet.getInt("votes"));
candidates.add(candidate);
}
return candidates;
} catch (SQLException e) {
e.printStackTrace();
}
} catch (DaoException e1) {
e1.printStackTrace();
}
return null;
}Temos então a interface ordenada:
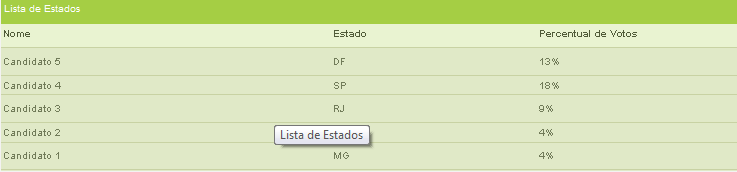
Quais informações de contexto estão disponíveis e como obtê-las
Através do método “source.getDouicontext()”, disponível no objeto de source que é passado como parâmetro no método “loadData()”, public void loadData(SessionConfig sessionConfig, TabularSource source, ITransaction transaction), podemos ter acesso a informações de contexto.
Exemplo:
source.getDouiContext().getRequest();
A seguir são citados alguns dos métodos comumente mais utilizados:
getRequest
public IServiceInterfaceRequest getRequest()
Retorna o request.
Este método traz informações sobre a requisição de onde o source foi chamado. A partir deste método é possível trazer outras informações importantes, como:
getAttributeNames
Enumeration<String> getAttributeNames()
Retorna uma coleção de nomes de atributos passados na requisição.
getParameterNames
Enumeration<String> getParameterNames()
Retorna uma coleção de nomes de parâmetros passados na requisição.
getServiceInterfaceInstanceId
String getServiceInterfaceInstanceId()
Retorna o ID da instância de interface do serviço de onde está o Source.
getServiceInterfaceInstanceConfig
ServiceInterfaceInstanceConfig getServiceInterfaceInstanceConfig()
Retorna o objeto ServiceInterfaceInstanceConfig que contém outras informações da Instância de interface.
getServiceInterfaceConfig
ServiceInterfaceConfig getServiceInterfaceConfig()
Retorna o objeto ServiceInterfaceConfig que contém informações da interface onde está sendo chamado este Source.
getServiceInstanceConfig
ServiceInstanceConfig getServiceInstanceConfig()
Retorna o objeto ServiceInstanceConfig que contém informações da instância de serviço.
getServiceConfig
ServiceConfig getServiceConfig()
Retorna o objeto ServiceConfig que contém informações do serviço.
getPageConfig
PageConfig getPageConfig()
Retorna o objeto PageConfig que contém informações da página onde está instanciado a interface que foi requisitada.
getSessionConfig
SessionConfig getSessionConfig()
Retorna a sessão do request.
getCookies
Cookie[] getCookies()
Retorna todos os cookies da requisição.
getCookie
Cookie getCookie(String cookieName)
Retorna um cookie passando o nome do mesmo.
getResponse
public IServiceInterfaceResponse getResponse()
Retorna o response, através dele é possível, criar cookies, deletar cookies, adicionar propriedades para o response, entre outros.
getTransaction
public ITransaction getTransaction()
Retorna a transação corrente, usada para operações de escrita e leitura em banco.
Diferenças no DataProvider para sources tipo table e tipo contentTable
Os Sources do tipo “table” fazem chamadas diretas às tabelas indicadas no campo “table”, conforme declaração de Source a seguir:
<source id="apuracao" type="table">
<table>APURACAO</table>
<fields>
<field id="name" dataType="string" name="Nome" />
<field id="uf" dataType="string" name="Estado" />
<field id="percentVotes" dataType="string" name="Percentual de Votos" />
</fields>
</source>
O Source apresentado busca informações diretamente na tabela “APURACAO”. Veja que o método “loadData()” da classe TableDataProvider chama o método “DouiDaoFactory.getTableDao().readData()”, responsável por buscar os dados na tabela indicada na definição do Source.
public void loadData(SessionConfig sessionConfig, TableSource source, ITransaction transaction) throws PortalException {
QuerySelect querySelect = buildQuerySelect(source, transaction);
TabularData data = DouiDaoFactory.getTableDao().readData(querySelect, transaction);
source.setData(data);
}
Os Sources do tipo “contentTable” fazem chamadas às tabelas indicadas no campo “table” e também a tabelas com informações de metadados, conforme declaração de Source a seguir:
<source id="apuracao" type="contentTable">
<table>TABLE_NAME</table>
<fields>
<field id="name" dataType="string" name="Nome" mask=”cpf” />
<field id="uf" dataType="string" name="Estado" />
<field id="percentVotes" dataType="string" name="Percentual de Votos" />
</fields>
<metaData>
<association/>
<workflow/>
<versioning/>
</metaData>
</source>No exemplo de declaração de Source, quando declaramos o tipo “contentTable” o método “buildQuerySelect()” da classe ContentTableDataProvider é sobrescrito, trazendo além das informações básicas da tabela “APURACAO” (name, uf, percentVotes), as informações de metadados deste Source.
A classe ContentMetaDataController é a responsável por prover estas informações de metadados através do método “selectMetaData()”.
public QuerySelect buildQuerySelect(TableSource source, ITransaction transaction) throws PortalException {
QuerySelect querySelect = super.buildQuerySelect(source, transaction);
ContentMetaDataController metaDataController = new ContentMetaDataController(null,ContentTableSource)source, transaction);
metaDataController.selectMetaData(querySelect);
return querySelect;
}
Sugestões para abordagem prática
A implementação de um DataProvider customizado, pode ser utilizada em casos como os seguintes:
- Montar Sources que consomem dados de um WebService
- Montar Sources que consomem dados de um arquivo XML
- Montar Sources com campos que necessitam de tratamentos especiais. Neste caso, pode-se utilizar também um PostLoadProcessor.
- Montar Sources que consomem dados de mais de uma tabela de banco de dados, ou seja, que precisam de consultas específicas.
- Montar Sources que consomem dados em diferentes Banco de Dados. Neste caso poderíamos também configurar Data Sources para serem utilizados no Source. Depois de configurado um DataSource em um arquivo XML, para utilizá-lo, basta definirmos na definição do Source, no nó “connectionId”, o nome do Data Source. Ex.: <connectionId>portalDS.xml</connectionId>.
Conclusão
Antes de implementar um DataProvider customizado, verifique se as definições padrões de um Source não atende a necessidade. É recomendável que seja utilizado os recursos da API Lumis para construção de um Source, ou seja, definições que não necessitam de customizações de classe Java para prover dados. Sabemos que há casos específicos, que não podem ser resolvidos com definições padrões de Sources. Para estes casos customizamos um DataProvider.
Em alguns casos, podemos utilizar outros recursos, como PostLoadProcessor que sua implementação não sobrescreve as definições padrões de Filtro, Paginação e Ordenação que na maioria das vezes é necessário. Em outras situações, podemos utilizar Datasources para termos mais de um banco de dados sendo utilizado e declarado de forma simples no douidefinition.xml. É preciso avaliar em cada caso a real necessidade de implementação de um DataProvider customizado.
Por último, para uma correta arquitetura em que seja respeitada a separação de camadas, é importante que o DataProvider possua em sua implementação apenas a lógica responsável pela obtenção e eventual tratamento sobre o formato dos dados para o preenchimento do source, deixando qualquer regra de negócios utilizada para essa obtenção a cargo de outras classes como Managers e Daos. Esse tipo de cuidado torna a arquitetura mais clara e aumenta o reaproveitamento das classes.
Autor: Esaú Freitas (XTI)